About
We release a 10000+ hours multi-domain transcribed Mandarin Speech Corpus collected from YouTube and Podcast. Optical character recognition (OCR) and automatic speech recognition (ASR) techniques are adopted to label each YouTube and Podcast recording, respectively. To improve the quality of the corpus, we use a novel end-to-end label error detection method to further validate and filter the data.
10,000 +
hours high-label data
with confidence >= 95%, for supervised training.
2400 +
hours weak-label data
0.6 < confidence < 0.95, for semi-supervised or noisy training, etc.
22400 +
hours audio in total
consists of both labeled and unlabeled data, for unsupervised training or pretraining, etc.
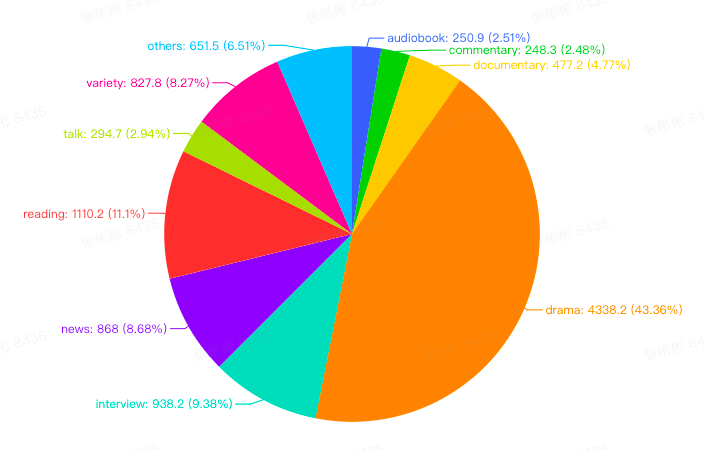
Diversity
The WenetSpeech can be mainly classified into 10 categories according to speaking styles and spoken scenarios.